
Hello again on a shiny shiny Sunday in April 2024!
In my last article I described how to deploy a containerized Blazor app to the Azure cloud. This is great, but it really needs some clarification, why we would ever create any application with Blazor - and what is so special about it. This post is part of my series to inspect various frameworks. I am familiar with TypeScript and React combination due to my long history with these technologies in the past. To educate myself and also my readers, I will use my current break from customer projects as an opportunity to write about Microsoft world’s tech stack. After bonding with Blazor, my plan is to come back to writing about React and TypeScript (if I am not busy with a customer project) and finally write my conclusions after playing with these both “pets”. But before that, let’s dive one more time into the deep blue Azure ocean, riding on the back of the wild Blazor whale!
Blazor’s Two Hosting Models
Unlike any other web framework, Blazor natively supports two different hosting models - Blazor WebAssembly and Blazor Server.
Blazor WebAssembly
When you use Blazor WebAssembly hosting model, your application runs client side in the browser on top of the .NET runtime that is based on WebAssembly (WASM). WebAssembly allows C# code to be compiled to bytecode that browsers can execute. To render the user interface, the Blazor WASM interacts with browser’s DOM model. Building a data driven web application means that your application has to access a database to get the actual data (to ride on) The Blazor WebAssembly however has the same limitations as all other client side web frameworks do (like React, Angular and Vue). Most remarkably, they can’t access the database directly. Instead, you are forced to write an extra web API layer between that provides the web app with an access to the database. This API is often also called a BFF, or backend for frontend, which is not to be confused with a generic (external or internal) API Gateway.

Blazor Server
Blazor Server hosting model, on the other hand, simplifies things quite a bit because your web application does not require you to implement a BFF (Web API) between the web application and the database itself. Since the Web app already resides on the server, not in the browser, it does not need to access the server at all - it’s already there right in the cockpit!
This makes Blazor Server-based webapps inherently simpler to implement than typical client-side web applications. It also has the benefit that your browser does not need load any JavaScript (or WebAssembly) bundle to be executed on the client side at all. This makes the web application start faster and it adds also some extra safety to the architecture. Namely, in a typical client side web application, the client application cannot store any sensitive tokens, such as database access keys or API keys to access internal APIs. The Server-side Blazor, on the other hand, can happily keep secret keys needed to directly access databases.
When the user interacts with the Blazor Server App, no HTTP request are being fired at all between the user and the server. User’s interactions with the application, such as mouse clicks and key presses, are transfered to the Blazor Server App over SignalR, which is a ultra-modern protocol built on Web Sockets. SignalR takes care of the traffic between the browser and the server-side app. It automatically
minimizes the amount of data required to update the UI. Instead of fully reloading the page, like in traditional server side applications,
SignalR makes sure that only minimal data snippets are transferred - just what is needed to change the view to correspond the actual state change. This SingalR based communication is made possible by a minimal JavaScript file blazor.server.js that is loaded into the browser at the start of the session.
Let’s Create an API-less Data Driven Web Application
Now that Blazor Server framework enables us to build a clean server-side web application without APIs in between, let’s take all advantage out of this and build a next generation data-driven API-less Blazor Server application to directly interact with the database. See the next iteration of our Blazor sample app Kalabaw Foods, that extends the earlier created food store example by adding Product and Category models and a database migration.
The step-1 iteration of the Kalabaw Foods online store uses .NET entity framework core and PostgreSQL database. This choice, of course, contradicts my previous writings where I suggested using MongoDB to store both small and big data. Clearly, entities such as products or categories fall under the definition of small data, because the number of different products and categories does not grow exponentially, as it usually requires precise productization and classification, which is slow work. This kind of small data, where object relationships matter, is the best food for relational databases. Therefore I did not apply MongoDB or another document database to power our emerging food business.
But that time will inevitably come when the business of our imaginary food entrepreneur in the example app grows and we need to go event-driven and start streaming real time data from our dozens meat mincers into our monitoring application. After all, we do not want production machines to break down due to overheating in the face of huge demand.
Getting Started
To help you getting started with whatever business fits you, I created a Blazor server sample app and I wired it up to use PostgreSQL (instead of Microsoft’s SQL Server) as its database. I packaged it into Docker containers to make it as easy as possible for you to run it on your machine. Check out my repository here to get started. I advice you to get busy and clone the repository right now: git clone git@github.com:develprr/KalabawFoods.git And then check out the latest development branch: git checkout step-1-adding-ef-core-and-postgresql Change dir to the front end app inside the project and make sure that the front end builds on your machine: cd KalabawFoods.FrontEnd dotnet build
Why Run Applications in Docker Containers
It is critical to every software project to keep the development environment maintainable. It’s a common mistake for impatient developers not to use any containerization technique for their projects when they start implementing a new project from scratch. They often just install all dependencies, such as databases, natively on their machines. This works great for them until a new developer joins the team or if they have a longer break from their development effort. When a new member joins the team and installs the same tools on their machines, chances are high that they run into problems because of slightly different software versions. It also may occur that you can’t get your project working anymore after a longer break from the project because there have been third-party updates to dependencies in the meantime and they aren’t compatible anymore with your configuration. Therefore, packaging your databases, services, backends and frontends in containers from the very beginning will make it easier for you to continue developing the project when you return after a break. It’s also a great thing that a new developer on the team can get the project running by just typing one command:
docker compose up -d

Of course, they have to first install the Docker engine. But even this can go wrong if you don’t choose the right installation method. If you use Ubuntu OS either natively or under Windows in WSL2 subsystem, this is the right method:
Install Docker using the repository
If you use Ubuntu in WSL2 under Windows, don’t use Docker Desktop for Windows in combination with Linux in the subsystem. It’s a mess because that configuration isn’t fully compatible with native Linux Docker installations - the differences in network addresses will be causing configuration problems, causing headache especially if some developers use Mac, some Windows with Linux subsystems and some even a native Linux.
Almost Everything Starts With Page Navigation
Coming back to our imaginary online food store application with Blazor and .NET that allows people to buy different kinds of food items online. When developing this sort of an application, it doesn’t take long before you run into this age-old problem that there are more search results than you can naturally display on a single page. I cannot recall a single project that has not addressed this issue. Our Kalabaw Foods online store is no exception. When the number of products available in the store grows to dozens, you need to start thinking seriously about pagination. Everybody knows the classic “boring” pagination with page numbers in a horizontal row and arrow-shaped navigation buttons to the left and right of the row. Maybe this pagination is so 90’s? Shouldn’t we rather consider infinite vertical scrolling that lazily loads more content? Perhaps, but for some reason all major online stores seem to be still sticking to the old school page navigation. Have a look at Amazon.com:
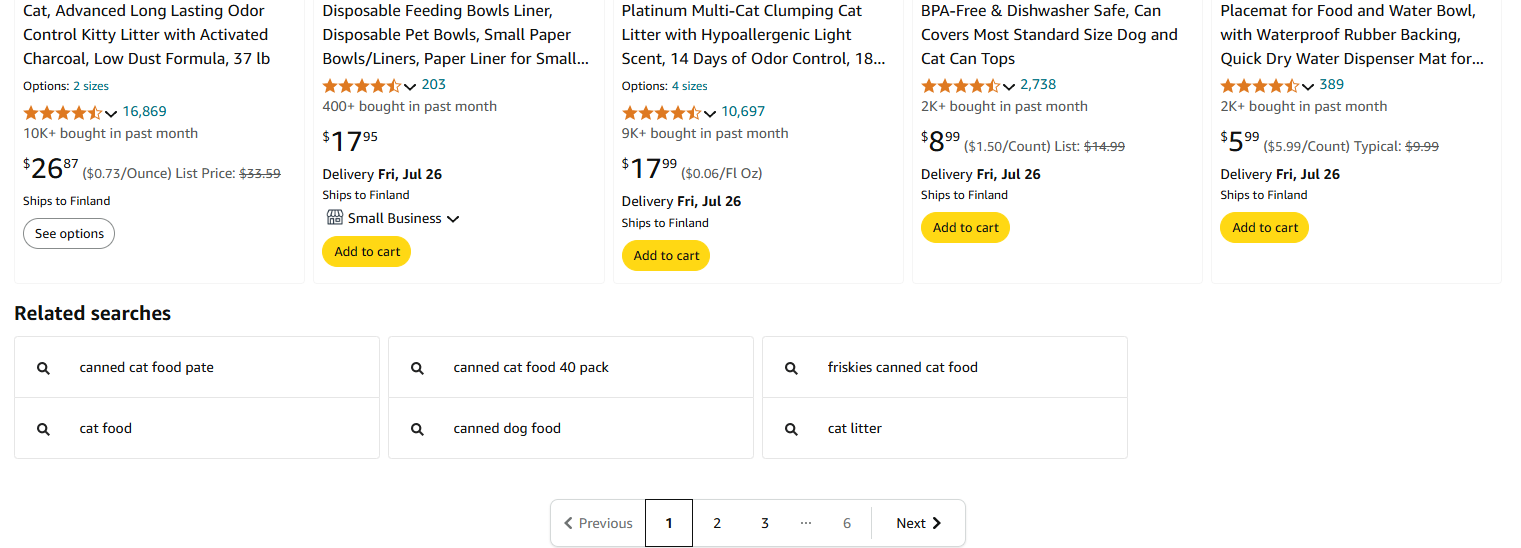
And if you don’t believe, just google!

Clearly, those corporations have all the money they need to code (and even maintain) whatever next generation navigation component, yet they still stick to the basic old one. There must be a reason for it!
From Page Navigation to Migrations
Yes, we too want a page navigation component for our products! But before creating one, we just need to have enough items on the store so we can actually develop and test it. Since the items are loaded from the database to the UI, we must first add more of them to the database.
Let’s check first the available migrations so far:
dotnet ef migrations list
Okay, the list shows that there is no migration yet dedicated to adding more products. So let’s add the migration:
dotnet ef migrations add MoreProducts

That generates the skeleton for the migration that will add more products. Now let’s define more products for our food store and add our food content to Up method of the migration:
Our online food store is making history. Not only did we add nine more products to our offering but enriched our selection with an entire food category. Soups!
Have a look at the migration file in the repository - or if your appetite is growing, just check out the entire branch to your machine to fill your own database with these delicious foods: git clone git@github.com:develprr/KalabawFoods.git And then check out the latest development branch: git checkout step-2-adding-more-products Now we are ready to progress to the next step and see how to make the UI cope with this new abundance.
I’ll talk to you later when I return from my lunch break. It might take a little while!
